Photo OCR - Sliding Windows
اولین مرحله از pipeline مسئله Photo OCR تشخیص متن است. به صورتی که اگر عکسی به مانند تصویر زیر داشته باشیم، مناطقی که متن در آن وجود دارد (مستطیلهای قرمز رنگ) را تشخیص دهیم. تشخیص متن یک مسئله غیرمعمول در computer vision است. زیرا بر اساس طول متنی که میخواهید پیدا کنید، نسبت ابعاد مستطیلهای قرمز رنگ مشخص شده میتواند بسیار متفاوت باشد.

برای بحث کردن در مورد چگونگی تشخیص چیزی در عکس، با تشخیص عابرین پیاده در یک عکس شروع میکنیم و سپس ایده به دستآمده از آن را برای تشخیص متن به کار میبریم. عکسی مانند تصویر زیر را داریم و هدف تشخیص عابرین پیاده در آن است. اگر به شکل زیر نگاه کنید، تمامی مستطیلهای قرمز رنگ که عابرین پیاده را مشخص کردهاند، تقریباً ابعاد مشابه و ثابتی دارند. هر چند ممکن است که فاصله عابرین پیاده در عکس متفاوت باشد و به همین جهت اندازه مستطیلهای مشخص کننده آنها متفاوت باشد، ولی نسبت ابعاد آنها (اندازه طول به عرض آنها) تقریباً یکسان است و به همین جهت این مسئله از مسئله تشخیص متن در عکس سادهتر است.

جهت طراحی یک سیستم تشخیص عابر پیاده به شکل زیر عمل میکنیم. فرض کنید نسبت ابعاد \(82 \times 36\) را برای عکسهایمان انتخاب کردهایم. پس مجموعهای زیادی از دادههای مثبت و منفی (عکسهایی که عابر پیاده هستند و عکسهایی که عابر پیاده نیستند) را جمعآوری میکنیم.

سپس یک الگوریتم شبکه عصبی یا الگوریتمی دیگر را آموزش میدهیم تا عکسی در اندازه \(82 \times 36\) را به عنوان ورودی دریافت کند و بتواند عکس را بر اساس اینکه عابر پیاده است یا خیر طبقهبندی کند.
حال فرض کنیم عکس جدیدی داریم و میخواهیم عابرین پیاده موجود در عکس را تشخیص دهیم برای این کار مستطیل \((82 \times 36)\) را از عکس انتخاب و تشخیص میدهیم که این قسمت از عکس دارای عابر پیاده است یا خیر سپس پنجره را حرکت میدهیم به سمت راست و دوباره تشخیص میدهیم که این قسمت شامل عابر پیاده است یا خیر (کادر سبز رنگ در تصویر زیر) و این کار تا اسکن کامل کل عکس توسط این پنجره ادامه میدهیم.



میزان حرکت به سمت راست این پنجره را پارامتر اندازه گام (step-size parameter) یا پارامتر استراید (stride parameter) مینامند. هر چه اندازه آن کمتر باشد، دقیقتر ولی از لحاظ محاسباتی پر هزینهتر خواهد بود.
در مرحله بعد میتوان پنجره لغزنده روی عکس را بزرگتر و همین کار را تکرار کرد. البته منظور از بزرگ کردن پنجره به این صورت است که قسمت بیشتری از عکس را انتخاب کند ولی هنگام دادن آن به الگوریتم طبقهبندی دوباره آن را به \(82 \times 36\) تغییر اندازه میدهیم. این کار را برای پنجرههایی با اندازههای مختلف تکرار میکنیم و امیدوار خواهیم بود که الگوریتم یادگیری ما بتواند عابرین پیاده موجود در عکس را تشخیص دهد.
حال برگردیم به مسئله خودمان، یعنی تشخیص متن در یک عکس. مشابه مثال بررسی شده میتوان با استفاده از نمونههای مثبت و منفی زیاد، یک طبقهبندی کننده را آموزش دهیم.

با داشتن همچین طبقهبندی کنندهای میتوان آن را روی یک عکس جدید به کار ببریم. اگر مستطیلهای کوچکی را روی عکس به عنوان پنجره لغزان استفاده کنیم، شکلی مشابه زیر را به دست خواهیم آورد.


مقیاس دو عکس با هم برابر است و در عکس فوق از رنگ سفید به عنوان جایی که الگوریتم مطمئن است متن وجود دارد استفاده شده است. رنگهای متفاوت از خاکستری میزان احتمالهای وجود متن در آن بخشها را نشان میدهد (روشنتر احتمال متن بودن بیشتر) اما هنوز کار تشخیص متن تمام نشده زیرا میخواهیم مستطیلها را روی همه متنها داشته باشیم. برای رسیدن به این هدف در مرحله بعد عملی که به اسم اپراتور انبساط (expansion operator) مشهور است را روی شکل اعمال میکنیم. در حقیقت این عملگر تمام قسمتهای سفید رنگ را منبسط کرده (برای مثال به تعداد 5 پیکسل اطراف قسمت سفید رنگ را هم سفید میکند.) و عکس به دست آمده در مرحله قبل به شکل زیر تغییر پیدا میکند.

چنانکه ملاحظه میکنید هر قسمت سفید رنگ در عکس اصلی در تصویر جدید گسترده شده است. در مرحله آخر بر اساس اینکه طول یک نوشته از عرض آن بیشتر است، قسمتهای سفید رنگ با نسبت ابعاد غیر متعارف را مانند آنچه که در شکل زیر مشخص شده، حذف میکنیم (کادرهای سفید رنگ که با ضربدر قرمز مشخص شدهاند).

البته واضح است که متاسفانه ممکن است بعضی از نوشتهها، که نسبت ابعاد غیر متعارف دارند را هم از دست بدهیم. مانند دایره قرمز رنگ در شکل زیر.

پس تشخیص متن در عکس به این صورت انجام میگیرد. حال میتوانیم قسمتهای به دستآمده را جدا کنیم و به مراحل دیگر پاپلاین بدهیم.
قسمت دوم پاپلاین تشخیص کاراکترها بود. در این مرحله هم یک الگوریتم یادگیری با نظارت را با فراهم کردن نمونههای مثبت و منفی زیاد آموزش میدهیم.
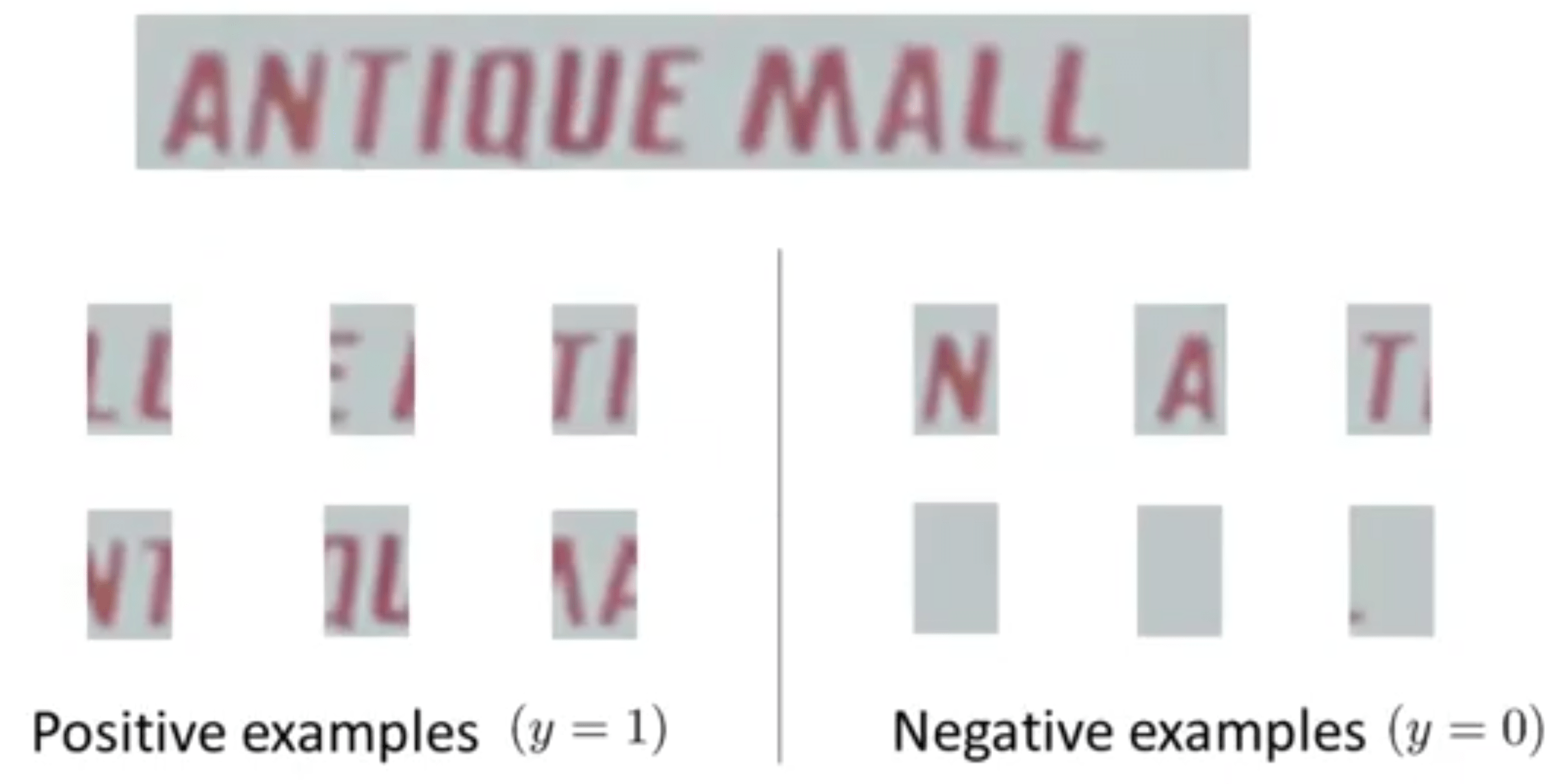
کاری که باید انجام دهیم آن است که به عکس نگاه کرده و تشخیص دهیم که بین دو کاراکتر درست در وسط تصویر، فاصلهای وجود دارد یا خیر. شکلهای سمت چپ در بالا چون فاصله بین دو کاراکتر را شامل میشوند، نمونههای مثبت و عکسهای سمت راست نمونههای منفی هستند (زیرا نمیخواهید که یک کاراکتر را از وسط نصف کنید). با آموزش چنین طبقهکنندهای متن جدا شده از عکس اصلی که در مرحله قبل به دستآمده است را توسط پنجره لغزان اسکن کرده و امیدوار خواهیم بود که الگوریتم یادگیری ما بتواند کاراکترها را به درستی از هم جدا کند (در شکل زیر فقط دو پنجره پیاپی نشان داده شده است، این پنجره باید کل تصویر را اسکن کند).


با مرحله آخر که شامل تبدیل کاراکترها به حروف است آشنا هستیم. این مرحله به مانند تشخیص ارقام از روی دست خط است. با انجام این مرحله کار ساختن اپلیکیشن Photo OCR که پاپلاین آن را در ۳ مرحله طراحی کرده بودیم به اتمام میرسد.