Photo OCR - Getting Lots of Data and Artificial Data
فراهم کردن مجموعه داده بیشتر
بارها اشاره کردیم که میتوان عملکرد یک الگوریتم یادگیری که از مشکل high bias رنج میبرد را بوسیله آموزش آن روی یک مجموعه داده زیاد بالا ببریم. اما از کجا چنین مجموعه دادهای فراهم کنیم؟ در یادگیری ماشین برای این کار ایدهای وجود دارد که آن هم تولید داده مصنوعی است. البته این ایده در مورد همه مسائل یادگیری ماشین قابل اعمال نیست ولی در برخی مسائل خاص با داشتن دیدی متفاوت و خلاقانه قابل اعمال است. اگر این ایده به مسئله یادگیری ماشین شما قابل اعمال باشد، میتواند راهی ساده برای به دست آوردن حجم نامحدودی داده باشد.
ایده تولید داده مصنوعی دارای دو شاخه اصلی است؛ شاخه اول ساختن داده مصنوعی بدون داشتن یا استفاده کردن از مجموعه داده، و شاخه دوم داشتن مقدار کمی داده و به طریقی تبدیل کردن آن به یک مجموعه بزرگ از داده.
ساختن داده مصنوعی بدون استفاده یا داشتن مجموعه داده
برای بحث درباره تولید داده مصنوعی بیاید از مرحله تشخیص کاراکتر اپلیکیشن photo OCR شروع کنیم.

میخواهیم عکسی را به الگوریتم بدهیم و تشخیص دهیم چه کاراکتری است. فرض کنید یک مجموع داده به شکل زیر جمعاوری کردهاید (در این مسئله بخصوص معلوم شده که رنگی بودن تصاویر کمک خاصی به الگوریتم نمیکند به همین دلیل از عکسهای سیاه و سفید استفاده کردهایم).

حال مسئله این است که چگونه یک مجموعه داده بزرگتر ایجاد کنیم؟ راه اول آن است که برای تولید داده مصنوعی از اول شروع کنیم (فرض کنیم دادهای نداریم). برای این منظور میتوان از کتابخانههای عظیم فونت که در کامپیوترهای مدرن وجود دارد استفاده کنیم.
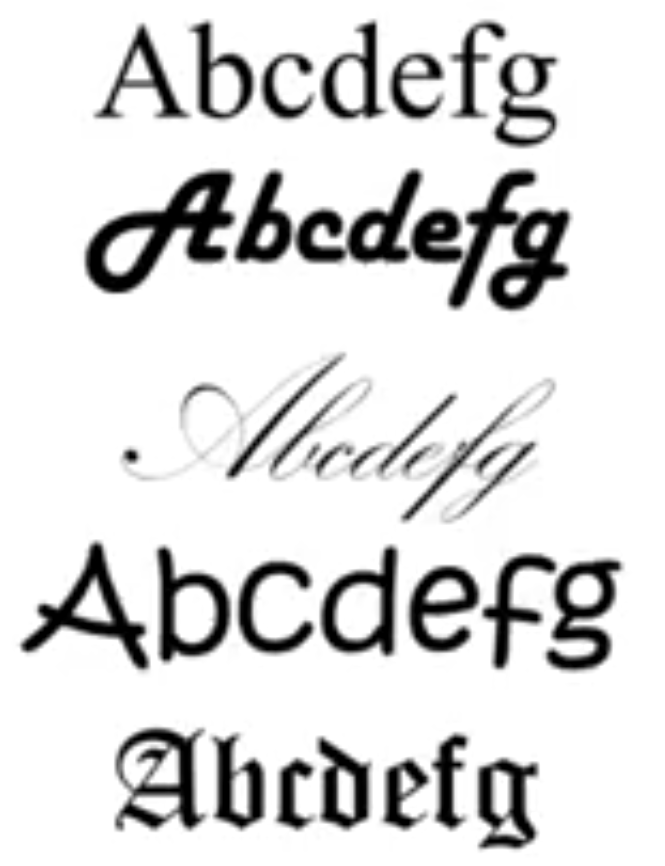
به این صورت که کاراکترها را از فونتهای مختلف انتخاب و آنها را به پسزمینههای متفاوت و تصادفی میچسپانیم. سپس با اعمال یک سری فیلترها، تغییر شکلها و ... بعد از انجام کار نسبتاً زیاد، اگر به درستی عمل کرده باشیم، میتوان مجموعه دادهای جدید به شکل زیر داشته باشیم.

اگر این شکل را با شکل قیل از خودش (مجموعه داده واقعی) مقایسه کنید، شباهتی بسیار زیادی بین این دو وجود دارد و میتوان گفت که مجموعه داده مناسبی را تولید کردهایم. بنابراین میتوان گفت که با استفاده از این ایده یک حجم نامحدود را برای الگوریتم یادگیری میتوانیم داشته باشیم.
ساختن داده مصنوعی با استفاده از مجموعه داده جمعآوری شده
راه دیگر استفاده از مجموعه دادههای موجود است. در این روش مانند تصویر زیر یک داده را نتخاب میکنیم (خطوط رسم شده تنها به جهت نمایش بهتر است در واقعیت این خطوط نباید وجود داشته باشند)، سپس با استفاده از تکنیکهایی 16 نمونه جدید را به مانند آنچه که در تصویر سمت راست مشاهده میکنید ایجاد میکنیم.
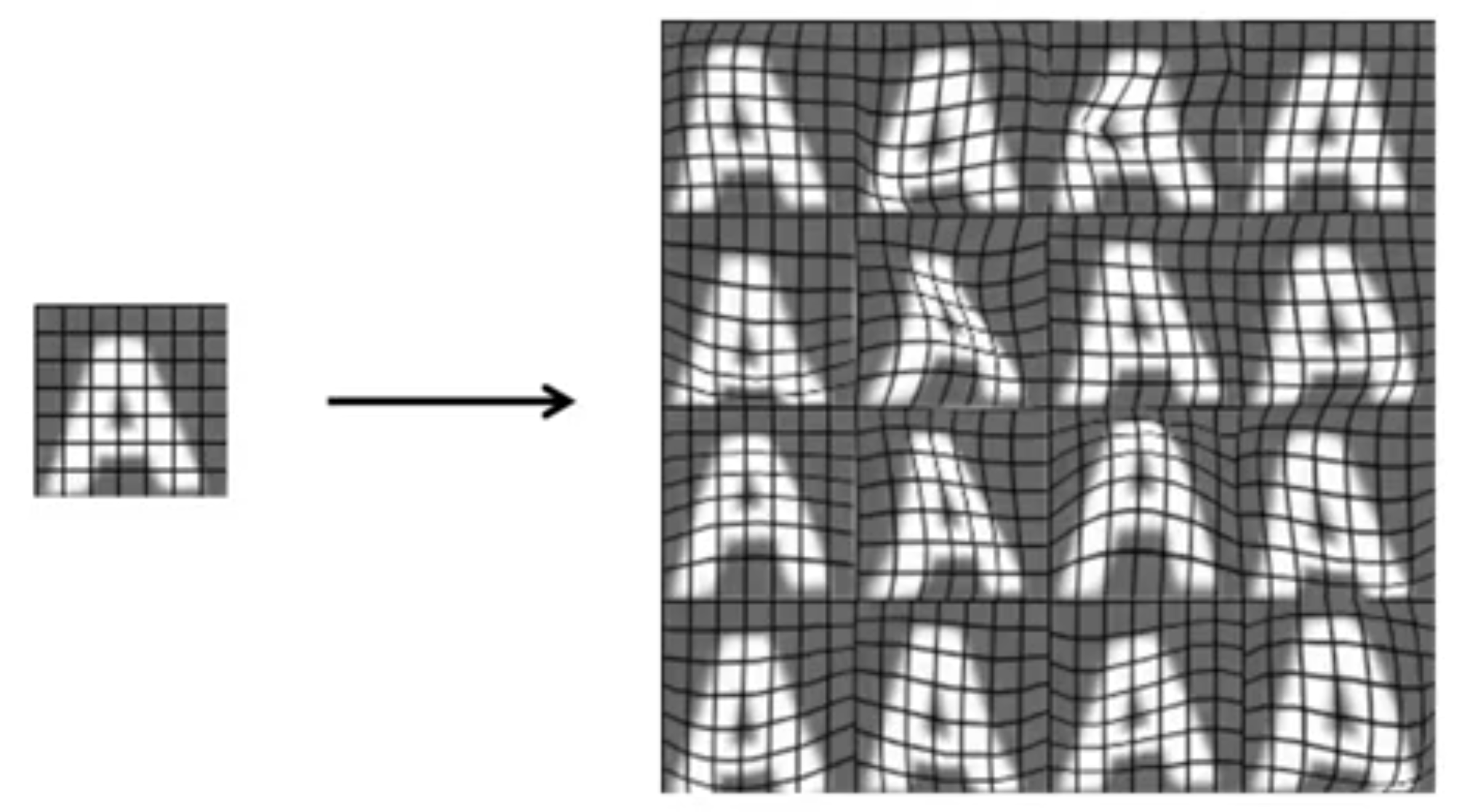
بنابراین ملاحظه میکنید که با داشتن یک مجموعه کوچک از دادهها میتوان مجموعهای به مراتب بزرگتر ایجاد کرد. البته باید یادآور شویم که برای اعمال این ایده به یک اپلیکیشن خاص، باید دیدی مناسب داشته باشید و ببینید که چه نوع تغییراتی روی مجموعه داده اصلی جهت تولید مجموعه بزرگتر منطقی است. برای مثال در یک حوزه کاملاً متفاوت به مانند تشخیص صدا، میتوان داده اصلی که شامل صدای اصلی است را با اضافه کردن نویزهای مختلف مانند، پس زمینه با صدای شلوغی محیط یا یک ارتباط موبایلی بد و ... به دادههای بیشتری تبدیل کنیم.
دقت داشته باشید که نویزهای اضافه شده در دو مورد بالا (تغییر شکل کاراکتر و اضافه کردن صدای پس زمینه به صدای اصلی) انواع نویزهای ممکن موجود در مجموعه داده را نمایندگی میکنند. ولی اگر همینطوری و بدون تفکر بخواهید به داده اصلی نویز اضافه کنید، هیچ کمکی به شما نمیکند. برای مثال در تصویر زیر به شدت روشنایی هر پیکسل یک نویز تصادفی گاوسین اضافه شده است که کاملا بی معنی است و هیچ کمکی به الگوریتم یادگیری ما نمیکند.

نکتههایی که باید برای تولید داده مصنوعی به خاطر داشته باشید:
- قبل از گسترش مجموعه دادههای خود مطمئن شوید که الگوریتم یادگیری شما از مشکل high bias رنج میبرد.
- «چقدر تلاش لازم است که 10 برابر دادههای فعلی را داشته باشیم؟» این سوال را ازخودتان یا گروهی که با آنها کار میکنید بپرسید. شاید تعجبآور باشد ولی اغلب اوقات زمان کمی برای تهیه چنین مجموعهای لازم است (چند روز تا چند هفته) و اگر واقعاً این طور باشد بهتر است که این کار را انجام دهید. زیرا میدانیم که با استفاده از دادههای بیشتر میتوان عملکرد الگوریتم خود را بالا ببریم.