Map Reduce and Data Parallelism
Map Reduce
الگوریتم Gradient Descent و انواع آن برای حجم دادههای زیاد و همچنین یادگیری آنلاین که در مورد آن بحث کردیم، تنها روی یک ماشین (کامپیوتر) قابل اجرا هستند. ولی برخی مسائل یادگیری ماشین گاهی بسیار بزرگتر از آنچه هستند که تنها روی یک ماشین اجرا شوند و همین مسئله باعث میشود که دنبال الگوریتمهایی به اسم Map Reduce برویم. این الگوریتم اگر از Stochastic Gradient Descent مهمتر نباشد، به اندازه آن مهم است. ایده اصلی این الگوریتم را توسط Batch Gradient Descent توضیح میدهیم.
فرض کنید \(m = 400\) البته این الگوریتم برای دادههای بسیار زیاد نظیر \(m = 400000000\) به کار میرود. ولی در اینجا برای سادگی \(m = 400\) را انتخاب کردهایم:
کاری که این الگوریتم انجام میدهد به این صورت است که به اندازه ماشینهایی که در اختیار داریم، دادهها را تقسیم میکند. برای روشن شدن مطلب فرض کنید ۴ کامپیوتر در اختیار داریم. ماشین 1 از دادههای
استفاده و عبارت زیر را محاسبه میکند:
ماشین ۲ از دادههای
استفاده و عبارت زیر را محاسبه میکند:
ماشین 3 از دادههای
استفاده و عبارت زیر را محاسبه میکند:
و ماشین 4 از دادههای
استفاده و عبارت زیر را محاسبه میکند:
بالانویس روی temp اشاره به شماره ماشین دارد. بنابراین به جای اینکه محاسبه جمع از یک تا ۴۰۰ داده را توسط یک ماشین انجام دهیم، آن را توسط ۴ ماشین انجام میدهیم. در مرحله بعد نتیجه همه آنها را به مرکز اصلی میفرستیم و این مرکز آنها را ترکیب کرده و محاسبه نهایی را انجام میدهد:
عبارت آخر همان کاری است که توسط یک ماشین برای Batch Gradient Descent انجام میشد. شکل زیر نمایش تصویری آنچه است که بیان شد.
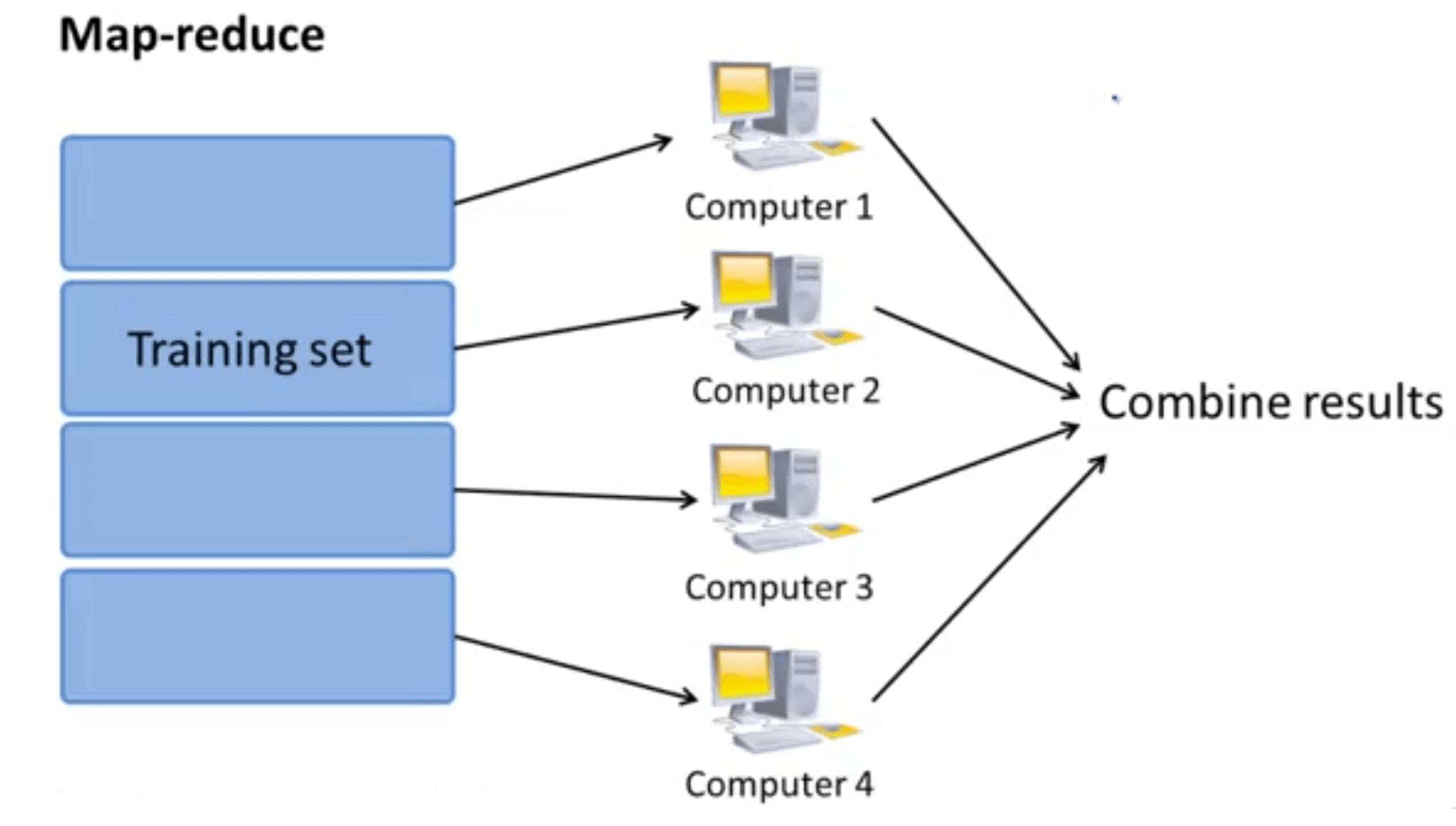
به لحاظ تئوری سرعت ما در این مثال باید ۴ برابر بیشتر شود. ولی به دلایل تکنیکی نظیر تاخیر شبکه (Network Latency) و ... معمولاً سرعت اجرا از ۴ برابر کمتر است ولی به هر حال سرعت بسیار بیشتر از قبل است.
یکی از سوالاتی که پیش میآید، آن است که برای چه الگوریتمهایی میتوانیم از این روش استفاده کنیم؟ برای جواب این سوال باید دید که آیا الگوریتم مورد نظر شما را میتوان به صورت محاسبه مجموع توابعی روی دادههای آموزش نوشت یا خیر. اگر این امکان فراهم باشد، که بیشتر الگوریتمها دارای چنین خاصیتی هستند، میتوان از روش Map Reduced استفاده کرد (برای دادههای بسیار زیاد). برای نمونه دیگر به بهینهسازیهای پیشرفته در مورد رگرسیون لجستیک اشاره میکنیم.
چنانکه احتمالاً به یاد دارید باید ۲ کمیت بالا را محاسبه میکردیم و همانطور که ملاحظه میکنید، هر دو کمیت را میتوان به صورت یک مجموع روی دادههای آموزش نوشت. بنابراین برای هر دو کمیت میتوان از روش Map Reduced استفاده کرد.
به عنوان آخرین نکته، در نظر داشته باشید که علاوه بر استفاده از Map Reduced برای زمانی که چند کامپیوتر در اختیار داریم، میتوان از آن برای یک ماشین که CPU آن از چند هسته پردازش تشکیل شده باشد هم استفاده کرد.

میتوان دادههای آموزش را به هستههای متفاوت فرستاد و هر کدام از آنها پس از محاسبه، نتیجه را به هسته اصلی جهت محاسبه نهایی بفرستند. در این حالت دیگر نیازی به نگرانی در مورد مسئله تاخیر شبکه و ... نیز وجود ندارد. بعضی از کتابخانههای جبر که برای زبانهای برنامهنویسی مختلف وجود دارند، این کار را به صورت اتوماتیک انجام میدهند.