Learning With Large Datasets
یادگیری با مجموعه داده بزرگ
دلیل بهتر بودن الگوریتمهای امروزه در حوزه یادگیری ماشین نسبت به گذشته نه چندان دور، در دسترس بودن دادههای بیشتر است. به همین جهت در این فصل میخواهیم در مورد الگوریتمهایی صحبت کنیم که با دادههای بسیار زیاد میتوانند به خوبی عمل کنند.
یکی از دلایل استفاده از مجموعه دادههای بزرگ را قبلاً در مورد طبقهبندی کلمههای گیج کننده مانند (to ،two ،too و ...) مشاهده و به جمله مشهوری اشاره کردیم که استدلال میکرد "برنده آن کسی نیست که بهترین الگوریتم را دارد بلکه آن کسی است که بیشترین داده را دارد" و نمودار عملکرد الگوریتمهای متفاوت در مقابل حجم دادهها به شکل زیر معرفی شد.
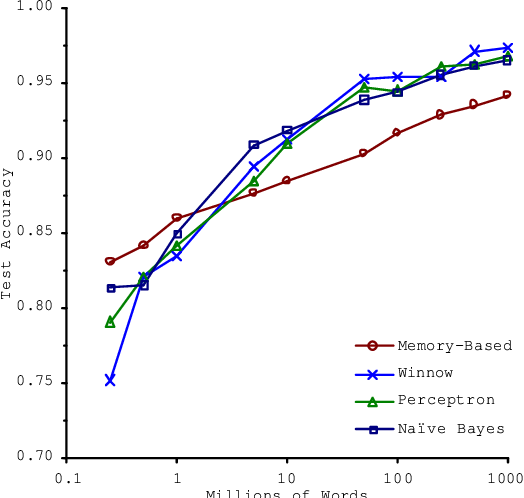
که در آن مشاهده میشود الگوریتمهای متفاوت تقریباً عملکرد یکسانی دارند و تفاوت زیادی بین آنها مشاهده نمیشود. ولی آنچه عملکرد الگوریتمها را بهبود بخشیده حجم دادههای استفاده شده است.
یادگیری با استفاده از حجم دادههای بسیار زیاد البته با مشکلات محاسباتی مربوط به خود همراه است. مثلاً فرض کنید تعداد دادههای شما برابر 100 میلیون باشد؛ \(m=100000000\) که برای برخی مسائل مانند وبسایتهای بسیار پرطرفدار این تعداد داده کاملاً واقع بینانه است. حال فرض کنید میخواهیم از Gradient Descent استفاده کنیم یعنی:
در این صورت چنانکه ملاحظه میکنیم برای محاسبه هر گام، الگوریتم باید به 100 میلیون داده نگاه کند و از لحاظ محاسباتی بسیار پرهزینه خواهد بود. بنابراین ملاحظه میکنید که به الگوریتمهای دیگری نیاز داریم که این محاسبات را به صورت بسیار مؤثرتری انجام دهند.
نکته مهمی که باید به خاطر داشته باشید این است که اول از خودتان بپرسید، به جای استفاده از این تعداد زیاد داده چرا با تعداد کم مثلاً \(m=1000\) الگوریتم را اجرا نکنیم؟ یعنی به صورت تصادفی از مجموعه دادهای که در اختیار ما است، 1000 نمونه را انتخاب کنیم، سپس چک کنیم که آیا به دادههای بیشتری نیاز داریم یا خیر؟ مثلاً اگر نمودار زیر به دست آید:
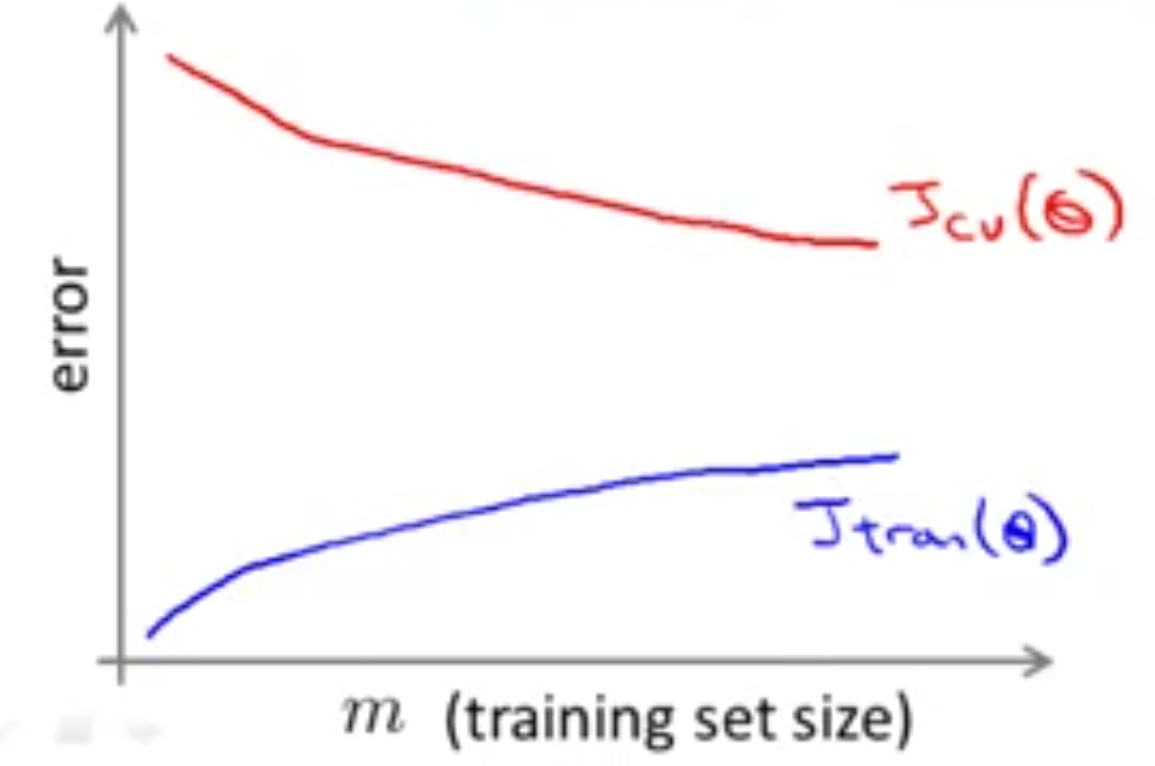
آنگاه مطمئن میشویم که با حالت High Variance روبهرو هستیم و قطعاً به دادههای بیشتری نیاز داریم ولی اگر نمودار زیر به دستاید:
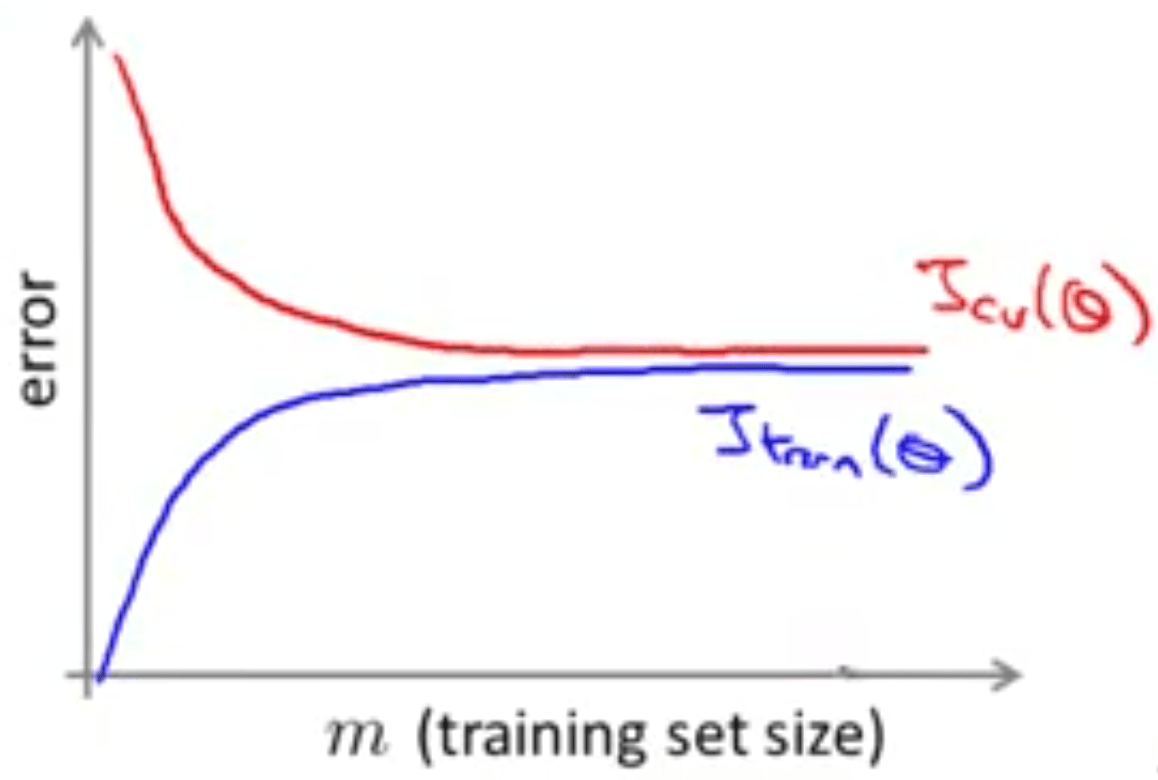
با حالت High Bias روبهرو هستیم و نیازی به دادههای بیشتری نخواهیم داشت. یا به عبارت دیگر به نظر نمیرسد افزایش تعداد دادهها بهبودی در عملکرد الگوریتم ما ایجاد کند.